
Datos Relacion
Un 
datos\_relacion mantiene un conjunto relacionado de
 datos_tabla, brindando servicios
para cargar y sincronizar esta relación con algún medio de persistencia.
datos_tabla, brindando servicios
para cargar y sincronizar esta relación con algún medio de persistencia.
Tipos de Relaciones
Entre las tablas se definen relaciones del tipo tiene como hijo a (la
inversa de depende de), esta es la relación que se utiliza para
definir las claves foráneas entre las tablas. Por ejemplo si un empleado
trabaja en un departamento, el empleado depende del departamento
(tiene una FK a esta tabla), entonces departamento es la tabla padre y
empleado la tabla hijo, esta es la definición de asociaciones 1-N o
N-1. Cuando se toma por ejemplo la relación "Un empleado tiene muchas
tareas" y las tareas son una entidad en sí mismas ahí se incluye una
tercera tabla que es la que permite la relación N-N:
(EMPL) 1---->N (EMPL_TAREAS) N<----1 (TAREA)
En este caso aunque la relación lógica es entre dos tablas, la
normalización requiere la inclusión de una tercera tabla. Como los
componentes de persistencia son un reflejo del diseño de tablas también
se definen tres tablas y dos relaciones: EMPL es padre de EMPL\_TAREAS y
TAREA es también padre de EMPL\_TAREAS.
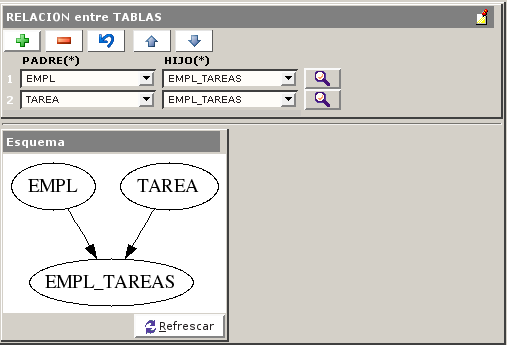
Definición
- AP por defecto: Administrador de persistencia a utilizar, ver más abajo la función que cumple.
- Modo debug: Para facilitar el entendimiento de lo que esta
sucediendo en la relación en cualquier punto de la ejecución se
brinda un esquema que muestra el contenido actual de cada tabla y
las relaciones que existe entre registros particulares. Este modo se
puede activar en ejecución (utilizando el método
dump_esquema) o en forma estática utilizando esta definición. Si se define en forma estática se muestra el esquema cuando se crea la relacion (al comienzo del request) y otro cuando se destruyo (al final del mismo). El esquema se grafica utilizando el componente ei_esquema en formato SVG.
- Suspender Constraints: No siempre se puede asegurar que las restricciones de base de datos se cumplan durante toda la sincronización. Existen situaciones en que el orden en el que se ejecutan las distintas sentencias puede incumplir temporalmente alguna restricción. Para estos casos se pueden suspender temporalmente el chequeo de constraints en la base, hasta el final de la transacción.
- Orden Automático: Tanto la carga como la sincronización siguen
un orden llamado
Orden Topológicode las tablas en base a las relaciones padre-hijo que existen entre ellas. Este orden no es posible definirlo si existe un ciclo en las relaciones (A es padre de B, este es de padre de..... que es padre de A), en este caso o en caso que el orden topológico no sea el deseado se puede definir uno particular. Cuando el orden automático esta desactivado se toma el orden determinado en la definición de las tablas.
- Tablas: Se adjuntan los datos tablas que forman parte de la
relación, el identificador permite nombrarlas dentro de la relación
tanto en la definición como en la programación. Así por ejemplo si
se define una tabla
personaen la relación, desde el código se la nombre como$relacion->tabla('persona'). Es posible determinar topes mínimos y máximos de filas que puede tener cada tabla en la relación.
- Relaciones: Se definen las relaciones padre-hijo entre las tablas, especificando los campos comunes entre las tablas.
Primitivas
En general el datos_relación va a estar asociado a un
componente CI, y es desde allí es donde se
consumen las primitivas disponibles. La mejor forma de entender las
primitivas es revisando el
API,
a continuación se dan ejemplos a manera de resumen de las primitivas más
utilizadas:
Carga
La forma más común de cargar una relación es a partir de una restricción
de las tablas raíces (aquellas que no tienen padres), para esto se
utiliza el método cargar: $relacion->cargar(array('id' => 8));,
para formas más particulares de cargar la relación ver el
API del administrador de persistencia.
Trabajo en memoria
El trabajo posterior a la carga generalmente se realiza a través de las
tablas relacionadas, la forma de
acceder a un componente tabla es así:
$relacion->tabla('nombre_tabla')->get_filas(), la principal
diferencia radica en que las operaciones sobre las tablas ya no son
aisladas sino que trabajan en el contexto de la relación:
- La eliminación de una fila de una tabla padre propaga la eliminación de las filas relacionadas en las tablas hijas.
- La inserción de una fila en una tabla hija se asocia con el cursor de la tabla padre.
El cursor de una tabla marca la fila actualmente editada, por ejemplo una operación edita tareas de empleados, en forma particular en algún momento de la operación se selecciona un empleado particular (supongamos Gomez) y se añaden tareas, el código de agregar una tarea sería algo así:
$rel->tabla('empleados')->set_cursor('gomez');
$rel->tabla('tareas')->nueva_fila('nombre' => 'Limpieza');
$rel->tabla('tareas')->nueva_fila('nombre' => 'Monitoreo');
En lugar de explicitar el empleado en estas llamadas, se asume que estas tareas se asocian con el empleado actual, es decir el cursor actual de la tabla empleados. Esto permite encadenar comportamientos, por ejemplo a nivel de interfaz primero se selecciona un empleado y luego se trabaja sobre el (añadiendo, modificando y quitando propiedades básicas y anexas), en la acción de selección simplemente se explicita el cursor, mientras que en el resto de las acciones no se hace referencia a este empleado, y se asume el seleccionado.